
L’apprendimento automatico (machine learning) è un campo dell’informatica profondamente diverso dai tradizionali settori computazionali. Nei campi tradizionali gli algoritmi sono infatti insiemi specifici di istruzioni che devono essere eseguite dai computer, istruzioni che non cambieranno nel tempo a meno che uno sviluppatore non le modifichi. Gli algoritmi di machine learning sono invece progettati proprio per cambiare nel tempo in base ai diversi input, ai pesi assegnati alle varie variabili ed ai diversi output.
Algoritmi di machine learning si possono applicare agli ambiti più diversi, dal riconoscimento facciale ai motori di reccomandation, dagli algoritmi predittivi delle fluttuazioni della borsa alle auto a guida autonoma. Il machine learning è infatti applicabile alle più diverse categorie di problemi, ma ovviamente ambiti diversi richiedono algoritmi di apprendimento diversi, algoritmi che differiscono fondamentalmente in base al fatto che gli output siano o meno “etichettati” (labeled), cioè che sia noto o meno a priori l’output atteso, ed a come si vuole che l’algoritmo “impari”.
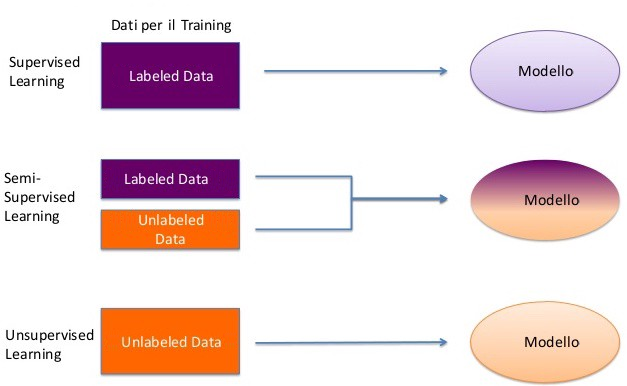
Due dei metodi di apprendimento automatico più comuni e diffusi sono l’apprendimento supervisionato (supervised learning) e l’apprendimento non supervisionato (unsupervised learning).
Nel supervised learning un insieme di valori di input “etichettati”, cioè i cui output desiderati sono noti a priori, vengono passati all’algoritmo. L’obiettivo è che l’algoritmo confronti il suo output effettivo con l’output desiderato e regoli il suo modello di conseguenza. Una volta che l’algoritmo è sufficientemente accurato è possibile utilizzarlo per classificare automaticamente migliaia di input “non etichettati”. Un esempio comune di supervised learning sono gli algoritmi di borsa che utilizzano dati storici e tendenze per prevedere le fluttuazioni future.
Nel unsupervised learning nessun dato di input è “etichettato” ed è compito dell’algoritmo trovare aspetti in comune tra i diversi dati per classificarli di conseguenza. Metodi di apprendimento non supervisionato possono ad esempio determinare per una Azienda l’archetipo del loro consumatore (il tipo di persona che ha maggiori probabilità di acquistare i loro prodotti), calcolando se ha maggiori probabilità di acquistare un certo loro prodotto un uomo o una donna, quale è l’età più comune dei loro consumatori e, tra le persone che hanno acquistato uno specifico prodotto, quali altri potrebbero acquistare.
Un sicuro vantaggio dell’apprendimento non supervisionato è che la maggior parte dei dati nel mondo reale è “senza etichetta” (unlabeled), quindi i metodi di apprendimento non supervisionato sono maggiormente utilizzabili perché non richiedono che l’output “corretto” corrispondente sia noto a priori per ogni input. Per lo stesso motivo c’è più possibilità di identificare nuove relazioni/associazioni utilizzando metodi di apprendimento non supervisionato perché si possono applicare ad immense quantità di dati apparentemente non correlati per determinare se emergono relazioni interessanti per il problema in analisi.
L’identificazione delle relazioni tra variabili è una componente fondamentale degli algoritmi di apprendimento automatico. Due importanti concetti statistici per la comprensione del funzionamento dell’apprendimento automatico sono la correlazione e la regressione.
La correlazione determina la misura in cui due (o più) variabili modificano insieme il loro valore. Una “correlazione positiva” rappresenta una situazione in cui le variabili si muovono in modo parallelo. Ad esempio, al giorno d’oggi, c’è una correlazione relativamente positiva tra bitcoin ed il mercato della crittovaluta, con l’aumento del prezzo del bitcoin anche le altre criptovalute tendono ad aumentare. Una “correlazione negativa” determina la misura in cui una variabile aumenta mentre le altre variabili diminuiscono. C’è ad esempio una correlazione negativa tra il tasso di disoccupazione ed il livello di spesa dei consumatori: poiché i consumatori spendono di più le imprese producono di più, il che le costringe ad assumere più lavoratori, il che riduce la disoccupazione.
La regressione va oltre la correlazione perché aggiunge capacità predittive. La regressione è usata per “esaminare la relazione tra una variabile dipendente ed una indipendente”: dopo aver eseguito un’analisi si dovrebbe essere in grado di prevedere il valore della variabile dipendente se la variabile indipendente è nota. Un esempio calzante potrebbe essere quello di un medico che cerca di determinare quale dosaggio di un farmaco somministrare ad un paziente. In questo caso la variabile dipendente è il dosaggio (perché dipende dal paziente) mentre il peso del paziente è una variabile indipendente. Il medico, conoscendo il peso del paziente, può determinare il dosaggio appropriato. Eseguendo una regressione un medico potrebbe quindi sviluppare una formula che, dato il peso di un paziente, determini il corretto dosaggio per uno specifico farmaco.
Esaminiamo ora alcuni comuni algoritmi di machine learning:
k-nearest neighbor (k-NN)
k-NN è un algoritmo di apprendimento automatico utilizzato per la regressione e la classificazione in cui l’output rappresenta l’appartenenza o meno dell’oggetto analizzato alla classe più comune tra i suoi k vicini (con k intero positivo). Nell’esempio che segue assumeremo che ci sia stato chiesto di eseguire la nostra classificazione basata su k = 1. Questo ci dice che l’oggetto dovrebbe essere assegnato alla stessa classe del suo vicino più prossimo.
Immaginate che la nostra macchina catturi l’immagine seguente:

Un momento dopo la nostra macchina cattura invece questa altra immagine:

Il nostro robot riconosce un’immagine sconosciuta e deve classificarla come stella o rombo. Poiché stiamo eseguendo una classificazione con k = 1 il nostro robot classificherà il nuovo oggetto come appartenente alla stessa classe del singolo vicino più prossimo. In questo caso il vicino più prossimo è una stella, quindi l’oggetto verrebbe classificato come stella.
Se avessimo eseguito una classificazione con k = 3 il nostro robot avrebbe esaminato i tre oggetti più vicini a quello nuovo, due stelle ed un rombo, ed anche in questo caso avrebbe classificato il nuovo oggetto come stella.
Questo potrebbe sembrare un metodo di “apprendimento” arbitrario ed inefficace, ma immaginate scenari in cui, ad esempio, certi oggetti vengono visualizzati costantemente in determinate parti dello schermo. In questi casi un semplice algoritmo k-NN potrebbe essere il modo più veloce per addestrare una macchina ad identificarli.
Decision Tree Learning
Gli alberi decisionali sono utilizzati per creare modelli predittivi il cui obiettivo è quello di generare un valore target basato su determinati input. Di seguito un semplice esempio di albero decisionale che si potrebbe utilizzare per decidere se giocare o meno a golf:
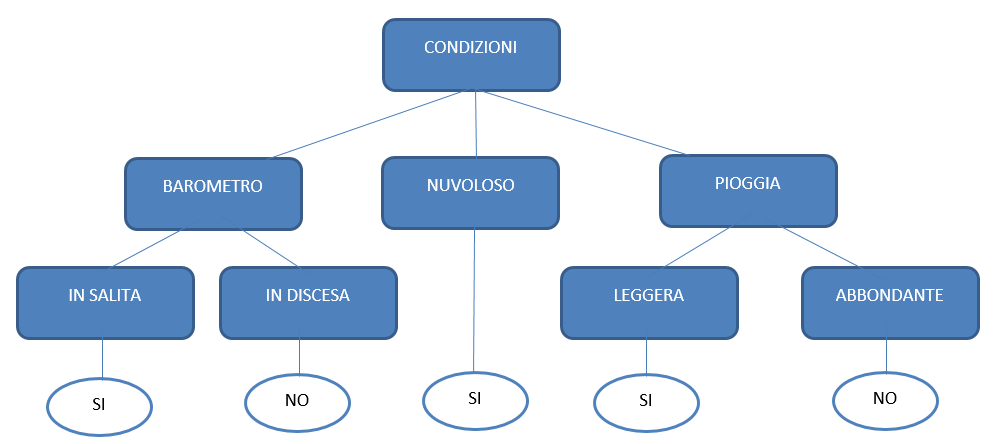
Gli attributi dei dati (pressione barometrica, nuvoloso, pioggia, ecc.) sono rappresentati da diramazioni, mentre gli output desiderati in base alla validità di tali condizioni sono rappresentati da foglie. Quando si costruisce un albero decisionale è necessario porsi le seguenti domande: Quali attributi (rami) includere ? Come suddividere questi attributi ? Quando dovrebbe terminare l’albero ?
Deep Learning
Con il termine deep learning ci si riferisce più a una classe generale di algoritmi di apprendimento automatico (o alla loro struttura) che ad un algoritmo particolare. Fondamentalmente gli algoritmi di deep learning operano in modo da emulare il cervello umano implementando delle “reti neurali” stratificate, cioè l’uscita da uno strato viene immessa nello strato successivo della rete, e ponderate, il che significa che alcuni input e output hanno un’influenza maggiore di altri. Gli algoritmi di deep learning, che possono essere supervisionati o non supervisionati, stanno già superando gli esseri umani in alcuni compiti cognitivi.
Regressione lineare
Gli algoritmi di regressione lineare operano per modellare i valori del target sulla base della relazione lineare tra una variabile indipendente e una variabile dipendente. Sviluppiamo la nostra regressione lineare calcolando la funzione “y = a x + b” per la quale la differenza tra i valori attesi e quelli reali è minima. Nella formula qui sopra y è la variabile dipendente (output) ed x è la variabile indipendente (input).
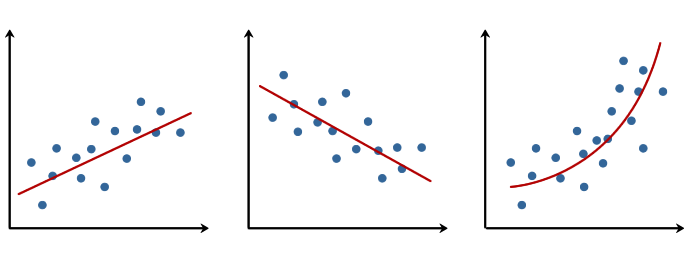
L’immagine a sinistra illustra una regressione lineare positiva (le variabili indipendenti e dipendenti aumentano insieme), l’immagine centrale illustra una regressione lineare negativa (le variabili indipendenti e dipendenti variano in direzioni opposte), e l’immagine a destra illustra una relazione esponenziale tra le variabili indipendenti e dipendenti.
Regressione Logistica (o modello logit)
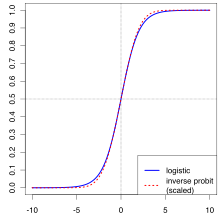
La regressione logistica è un algoritmo di classificazione supervisionato, cioè i valori passati all’algoritmo sono “etichettati” con i loro output desiderati. L’obiettivo è quello di confrontare l’output effettivo con l’output desiderato e regolare l’algoritmo di conseguenza. In particolare le regressioni logistiche sono utili quando la variabile dipendente è binaria (es: vincere o perdere) ed è possibile utilizzarle per stimare, in base alle variabili indipendenti, la probabilità che si verifichi un certo evento (es: vincere una partita). Una buona regressione logistica può prevedere con precisione i risultati attesi.
Macchine a vettori di supporto (SVM, Support-Vector Machines)
Si tratta di un altro algoritmo di classificazione supervisionato che, dato un insieme di esempi per l’addestramento , disegna un vettore tra le due categorie. Il concetto può, all’inizio, confondere. Vediamone un esempio: immaginiamo di costruire il nostro algoritmo in modo che differenzi cerchi e quadrati disegnando una linea che li separa.

L’algoritmo lavora per ottimizzare la linea di confine assicurandosi che i punti più vicini di ciascuna delle due classi siano il più lontano possibile l’uno dall’altro.
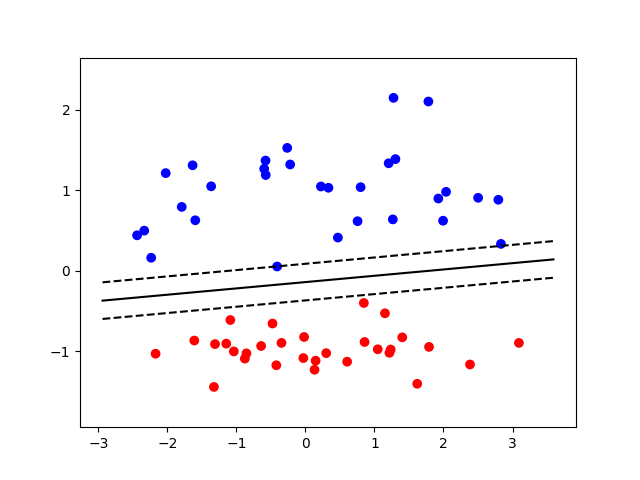
Questi punti più vicini sono gli “estremi” del nostro campione e definiscono i “vettori di supporto” (illustrati dalle linee tratteggiate qui sopra). La nostra linea di confine deve rimanere in ogni momento tra i vettori di supporto altrimenti rischiamo una errata classificazione. Una macchina a vettori di supporto potrebbe essere utilizzata per determinare se un’immagine contiene un gatto o un cane. In questo caso il vettore di supporto per la categoria dei gatti sarebbe definito da “un gatto che assomiglia ad un cane”.
Random Forests:
Le foreste casuali sono un popolare algoritmo di apprendimento supervisionato “di insieme” e possono essere utilizzate sia per la classificazione che per la regressione. Con “di insieme” si vuole intendere che l’algoritmo utilizza molti “predittori deboli” e li fa collaborare per formare un unico predittore forte. In una foresta casuale i predittori deboli sono singoli alberi decisionali mentre la foresta rappresenta tutti gli alberi decisionali fusi insieme per formare un modello più accurato (il predittore forte). Come si crea una foresta casuale? Molti alberi decisionali poco profondi sono creati da campioni casuali di dati. Ma i singoli alberi decisionali possono contenere errori perché non è garantito che i dati di input rappresentino accuratamente l’intero spazio del campione. Aggregando quindi i dati provenienti da alberi decisionali multipli le foreste casuali cercano di migliorare l’accuratezza delle previsioni eliminando gli errori/le distorsioni.
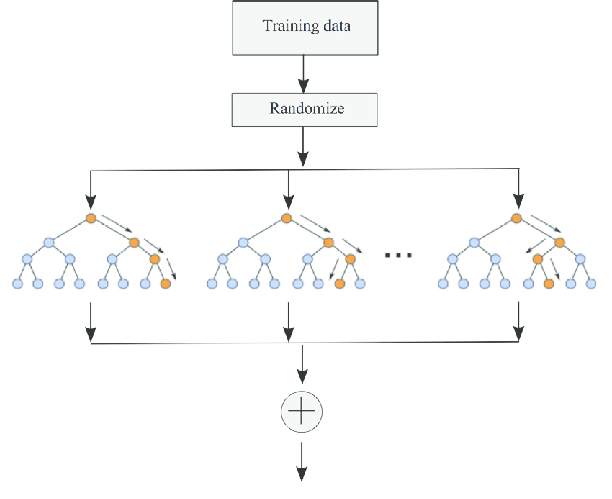
Immaginiamo ad esempio di voler comprare un’auto nuova. Sopraffatti dal numero di opzioni disponibili sul mercato decidiamo di consultare gli amici. Gli amici probabilmente ci chiederanno che tipo di caratteristiche stiamo cercando nell’auto e potremmo modellare questo feedback come un albero decisionale: ogni caratteristica (attributo) che gli amici ci chiedono di considerare rappresenta un ramo, e ogni ramo è diviso per le possibili risposte a quella caratteristica. Se per esempio gli amici ci chiedessero se vogliamo o meno guidare sulla spiaggia quel ramo sarebbe diviso in ‘quattro ruote motrici’ o ‘senza trazione integrale’. Dopo aver consultato molti amici e considerato molte caratteristiche diverse possiamo generare il predittore forte (identificare l’auto più adatta) includendo quelle più frequentemente raccomandate per l’auto da acquistare.
K-Means Clustering:
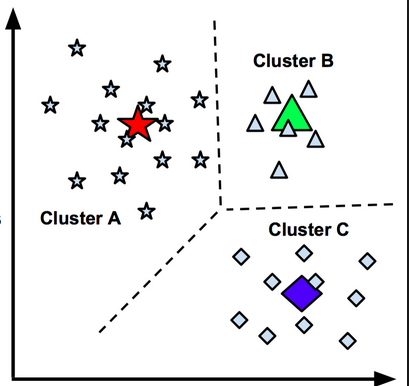
K-Means Clustering è un algoritmo di classificazione ad apprendimento automatico non supervisionato. Il valore “K” viene immesso dall’utente e si riferisce al numero desiderato di cluster (gruppi) nel set di dati. Il clustering è definito come “raggruppamento di un insieme di campioni in modo che quelli appartenenti ad un gruppo (o un cluster) siano più simili (secondo alcuni criteri) di quelli di altri gruppi”. L’algoritmo considera un campione di dati e lo separa al meglio in un numero K di cluster. L’onere di selezionare il numero appropriato di cluster è completamente a carico del data scientist. Rispetto ad altri algoritmi non supervisionati K-Means è incredibilmente veloce e potrebbe, ad esempio, essere utilizzato per identificare diversi segmenti di clienti in un mercato e, poi, per classificare i nuovi clienti come appartenenti ad una di queste categorie. Raccogliendo ulteriori dati su come si comportano i diversi segmenti di clienti le aziende possono generare previsioni accurate sui guadagni futuri, sul potenziale di crescita, sulla composizione demografica dei clienti, ecc.
Quindi quale algoritmo di apprendimento automatico dovrei usare ?
Questa è la vera domanda. In primo luogo è possibile restringere il campo di applicazione determinando se è necessario un algoritmo di apprendimento supervisionato o non supervisionato. Ricordate, se avete a disposizione gli output desiderati (etichette) per ciascuno dei vostri valori di input, allora vorrete usare un algoritmo di apprendimento supervisionato. Se invece volete che la macchina impari a classificare i dati, allora vorrete usare un algoritmo non supervisionato. I fattori più importanti da considerare quando si sceglie un algoritmo sono:
- La dimensione, la qualità e la natura dei dati
- Il tempo di calcolo disponibile
- L’urgenza del compito
- Cosa si vuole fare con i dati
- Precisione, tempo di training del modello, facilità d’uso
Lo schema che segue offre, dato il caso in analisi, alcune indicazioni su quale algoritmo provare per primo.
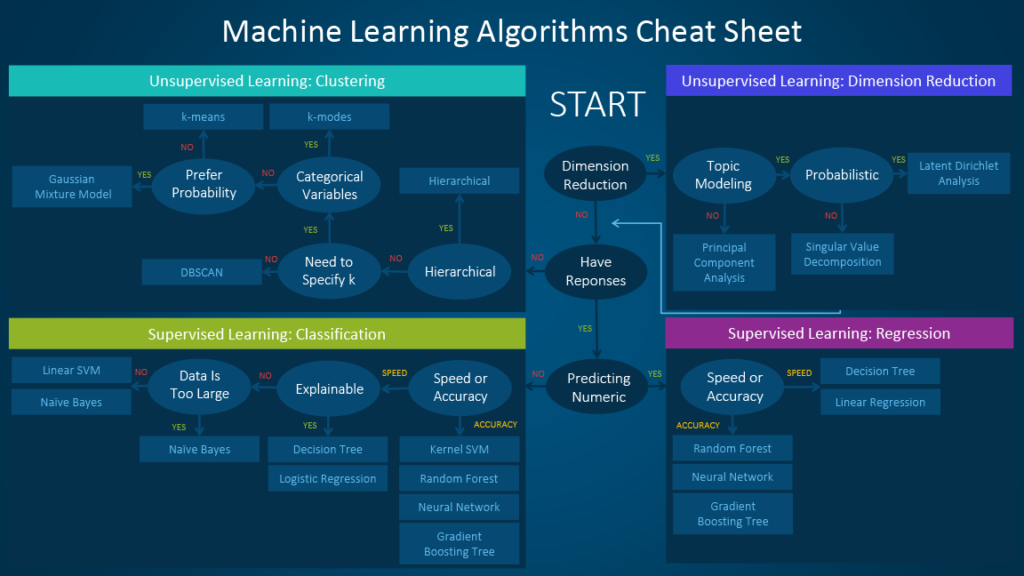
Lo schema deve essere usato solo come “regola generale”, a volte nessun percorso si applica perfettamente al nostro caso ed è per questo motivi che alcuni data scientist affermano che “l’unico modo per garantire l’identificazione del miglior algoritmo è provarli tutti”.